Journey through eventsourcing: Part 2 - designing a solution

The previous post left us at the beginning of the design phase - I and my team have gathered the functional and non-functional requirements for the system, and we were ready to start designing a solution for the problem. In this phase of our journey, we needed to come up with an architecture that would allow us to achieve the required consistency, availability, and throughput goals, and also be easy to evolve, maintain and explain. To do so, we spend some time brainstorming, evaluating, and experimenting with multiple architectures. In this post, I’ll touch base on some “head-first” architectures, why have we rejected them, as well as our final approach and the reasons for us to pick it.
Disclaimer
The events, systems, designs, implementations, and other information listed here are not in any way connected with my current work and employer. They all took place in 2017-2019 when I was part of the Capacity and Demand team at Redmart - retail grocery seller and delivery company. To the best of my knowledge, it does not disclose any trade secret, pending or active patent, or other kinds of protected intellectual property - and instead focuses on my (and my team’s) experience using tools and techniques described. Most of it was already publicly shared via meetups, presentations, and knowledge transfer sessions.
Series navigation
- Journey through eventsourcing: Part 1 - problem background and analysis - June 27, 2020
- Journey through eventsourcing: Part 2 - designing a solution - July 14, 2020
- Journey through eventsourcing: Part 3.1 - implementation - August 1, 2020
- Journey through eventsourcing: Part 3.2 - implementation - August 14, 2020
- Journey through eventsourcing: Part 4 - Pre-flight checks and launch - November 30, 2020
- Journey through eventsourcing: Part 5 - Support and Evolution - February 15, 2021
Recap: Declared project goals
Functional goals
- “Strong” consistency model for placing an order - overbooking must not happen, even in case of many concurrent customer requests and/or failure of service nodes.
- Build better tools for the planning team to manage the logistics capacity
- Change the way capacity was represented in the system
- Account for multiple types of capacity (logistics, warehouse, etc.)
- Build more user-friendly tools for visualizing and modifying capacity
Availability
- Service Level Agreement (SLA) - 99.9% aka 3 nines
- Service Level Objective1 (SLO) - 99.99% aka 4 nines
Performance
- <200ms 99th percentile for both reads and writes
- maintain the above at up to 10x the current peak second load for a long time2.
Fault tolerance
- System should be able to survive one node crash/restart without interrupting service
- During planned restart, no requests can be lost except the ones already being processed on the restarted node.
- During node crash, the system is allowed to lose some of the requests for a brief time - 3-5 minutes at most; after that system must restore full functionality without human intervention.
Consistency analysis
Here’s the scenario our system needed to support. We have two customers - let’s call them Alice and Bob, as usual. The orders they would place will be allocated to the same capacity pool - let’s call it 6pm slot (see the previous post for definitions). The pool can only accept one order. The real-time (aka wall clock) sequence of their interactions with the system and outcomes are as follows:
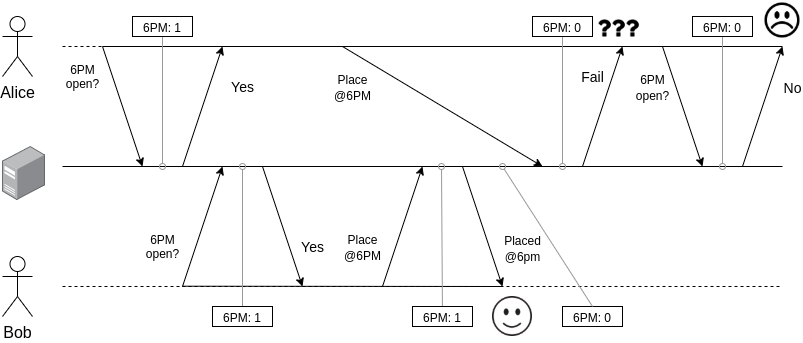
One thing to add here is that we only want one order placed, but it could be either one.
Here are the key observations we made from this scenario:
- Many clients: we need to support many concurrent clients, potentially competing for the same resources.
- Single-object updates: each update operation only touches a single pool of capacity.
- Reads can have relaxed consistency: it’s ok to show a slightly outdated view of capacity to the customers. There is some natural delay between the time when the capacity overview is displayed (read query) and reservation is attempted (write query), so showing the overview as it was “a few seconds back” is indistinguishable from the “race condition” scenario above.
This led us to the conclusion that we need a system with strong single-object consistency for writes and eventual consistency for reads. Further, since in case of a failure we want the customer to be redirected to healthy nodes, “sticky” approaches to consistency/availability are also not feasible.
Putting it all into one sentence: the system needed to build some total order of write operations submitted by many clients, consistent between all the nodes, but not necessarily matching the wall clock sequence of the requests. The most permissive consistency model that matches has these features is called Sequential consistency:
Sequential consistency is a strong safety property for concurrent systems. Informally, sequential consistency implies that operations appear to take place in some total order and that that order is consistent with the order of operations on each process.
See also: Jepsen Consistency Models
Architectures considered and rejected
To be frank, this kind of thorough and thoughtful consistency analysis I just described only happened after we presented the implementation proposal at the design review session - as a response to an unspoken, but the unanimous question “does it have to be that complex?” ![]() . However, we still did our homework well - we have had evaluated many other implementation approaches against the known use cases. Before we look at the final solution architecture, it is worth visiting the other, more “classical”, “straightforward” or “simpler” approaches, and why we rejected them.
. However, we still did our homework well - we have had evaluated many other implementation approaches against the known use cases. Before we look at the final solution architecture, it is worth visiting the other, more “classical”, “straightforward” or “simpler” approaches, and why we rejected them.
Push figuring out consistency to the DB level

Image source: not-my-problem.com
The “classical” approach - let the applcation call the database with the right settings - transaction isolation level in relational DBs (e.g. PostgreSQL) or read-concern / write-concern in NoSQL, such as MongoDB and many others.
There were multiple reasons for rejecting this approach:
- We wanted to have the application state in memory, to meet latency and throughput requirements (see the previous post)
- Scaling would be less straightforward - even though scaling databases is a well-researched topic, it still adds it’s own parameters to the equation.
- Finally, the existing system was built with this approach in mind, and a few significant issues and outages were attributed to consistency/latency/throughput issues arising from the use of this architecture.
Use optimistic concurrency

The general idea is to put a “version number” onto a record, and at the DB side only perform a write/update when the version number sent by the application matches the version number in the DB and if not - reject the write, assuming the app will re-read the record, re-apply the modification logic and retry the update. This technique is very popular, as it allows enforcing strong(er) consistency in a relatively straightforward way.
This approach works well if the majority of the updates are predicted to not face a conflict - if no conflict happens, the overhead compared to “don’t even bother about consistency” (aka Last Writer Wins) is marginal. However, the resource consumption and latency virtually doubles in case of a conflict, and in highly concurrent scenarios single request might face more (sometimes much more) than one conflict.
This is why we rejected this approach - our back of the envelope calculation showed that even at a 3x current rate, we would face latency spikes beyond our SLA. Moreover, certain capacity “types” we needed to support essentially needed to be represented as a single record3 - which would cause many conflicts right away.
Distributed locking

Image source: Pexels ![]()
In a non-distributed architecture(s), the common way to achieve strong consistency models is to employ some OS-level synchronization primitives to guard access to critical sections of the code. In this case, the concurrency model is “pessimistic” - all processes assume that conflict will happen, and always pay some price (acquire a lock, wait on a semaphore, etc.) to prevent it.
The OS-level primitives are unable to “synchronize” access between different nodes of a distributed system. However, there are some systems out there that can provide similar capabilities - such as Redis’ Redlock or Hazelcast.
We ruled out this approach for one theoretical and one practical reason:
- Theoretical: at the time of designing the system, we were not aware of Redlock, so we thought only a single-node locking with SETNX instruction is available. This invited the scalability and latency concerns - at one layer the application instances would need to wait to acquire the locks (“domain” contention) and deeper down the infrastructure stack, different Redis clients will also compete for Redis’ execution engine to handle their requests (“shared resource” contention).
- Practical: the Redis instance that we had in production at that moment had some weird configuration or networking issue. During an unrelated project, where Redis was used as a read-through cache I noticed that reading a single “record” from Redis was slower than from the source of truth.
See also:
- an insightful analysis by Martin Kleppmann on the distributed locks and Redlock in particular
- and Redlock’s author response to it
Personal opinion: I’m with Kleppmann on this (but I’m not an expert on the topic and I may be biased - I’ve read his book). If I were designing this system now, knowing about Redlock, I think I’d still reject the distributed locking approach.
Serialize through a queue

Image source: Needpix ![]()
The idea here is simple - when a request comes, don’t do anything but put it into a dedicated queue. Have one application instance listen to the same queue and process the messages as they come. This would ensure some total order of requests - namely, whatever order that single “listener” instance observes.
Interestingly, even though a single point of failure is clearly seen in this architecture, it was a relatively popular way to achieve “deduplication” and consistency in the organization - there were a couple of systems that relied on this mechanism to ensure “exactly once” semantics - albeit on less critical and non-time-sensitive tasks.
The approach was rejected for the obvious reason of having a single point of failure, added request latency and additional external dependency. On top of that, this approach called for adding “functional” complexity - since the request to our system is “synchronous” (customer’s browser waits for the response), and queue-based communication does not automatically imply “response” to the message, it would be necessary to build the “request-response” communication mechanism over the queue.
On a side note, at a glance some Kafka-based approach with sharding per capacity pool seems feasible now - so “serialize through a queue” might be a good architecture for this. However, at that time we haven’t had production-ready Kafka cluster, so it was not an option. The remark about “request-response” communication still holds though.
Final architecture
Let’s finally talk about the architecture we actually used and defended at that design review session(s). At a very high level it looked like this:
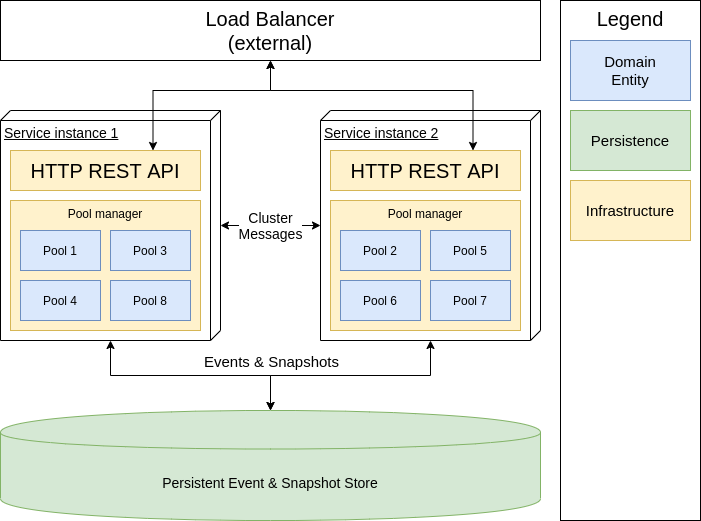
Consistency: We would represent each capacity pool as a single entity. To achieve the desired consistency model, there will be at most one instance of each entity across all the system nodes - this will eliminate race conditions between the nodes. Furthermore, access to the entity state will be protected from concurrent access, thus making entity business logic running in a single-threaded fashion. This way, we will ensure the total order of operations by passing all the updates through a single entity instance.
Availability: The paragraph above sounds as if we’re re-introducing a single point of failure - i.e. if the node running an entity is down, the entity will not be available anymore. This is partially true. First, the entities will be distributed between many nodes4, so if any node is down, only some of the entities will become unavailable. Second, the system will detect such cases, and redistribute the affected entities among healthy nodes automatically - it requires nodes to be aware of each other, and form a cluster. So, if a node crash, some entities will become unavailable for some time but will be automatically recovered in a short time.
Request handling: All instances of the system will expose the same REST API and are capable to serve both read and write requests. In case the request targets an entity that is located at the other node, the “internal” call between the nodes will be handled transparently to the client.
Performance: Each entity will have it’s full state available in-memory. There will be no external data sources to fetch, or external systems to interact with during handling the request, except making persistence calls when the state changes. It makes possible answering read-only requests purely from memory, and write requests will only need to interact with the database once - to save the update.
Persistence: Entities will use eventsourcing to save changes. - so instead of overwriting the state on each update, the entity will only append an event that caused the change. This will happen before the actual in-memory state is changed, so it also serves as some sort of write-ahead log - if an event is persisted successfully it becomes a fact. The entity’s event log is only read when the entity is (re)started - to rebuild the in-memory state. Further, to speed up recovery, entities will persist a snapshot of the state from time to time, so there’s an upper bound on the number of events to be processed during recovery.
CAP theorem
I’d like to further emphasize how we handle the availability concern. CAP and PACELC theorems are mathematically proven and there’s no way around them. However, being theorems they have very precise and strict definitions of what “consistency” and “availability” actually mean. By these theorems, the proposed system would be consistent, partition-tolerant, but not available - i.e. in presence of partition we favor consistency (correctness) over availability (the system works) and have a CP system.
The trick is that the “availability” definition is too strict for practical purposes. For example, you probably would not call the system unavailable if your request fails, but retrying the same request a split second later works perfectly fine - but it is not available from the CAP theorem perspective.
So, for practical purposes, there’s a “time horizon” of the availability - how much it takes a system to recover from partial or total failure. For the people-facing system such as ours, anything that recovers in less than 200ms is virtually indistinguishable from the perfectly available system, and recovery times of up to a few seconds are acceptable from time to time.
And in that sense, the system we built based on this architecture was almost totally available. But I’m jumping a bit forward - we’ll take a closer look at this in some of the future posts.
Key takeaways
There is almost always more than one way to do something - systems architecture and design is no exception. Choosing a good architecture style and metaphor is similar to laying a building foundation - choices made at this stage have an enormous impact on the quality, speed, and success of the project implementation. I strongly believe that allocating some resources to experimentation and design discussions during the early phases of the project is a good investment of time even in the most time-constrained situations.
Having spent a week or two investigating, experimenting and analyzing different architecture styles, I and my team came to the conclusion that eventsourcing offers the strongest foundation to achieve consistency, availability, scaling, performance and other goals. One of the key findings/decisions were to have different consistency models between reads and writes, and to achieve the acceptable availability levels by the means of rapid fully-automatic recovery from a failure.
Wrap up
To sum up: we took a careful and thoughtful approach to consider and analyze multiple implementation approaches and architecture styles. Most “classical”, “lightweight” or “straightforward” sparkled concerns about either consistency, availability, or performance of the solution. Eventsourcing approach, despite being more novel to the team and more inherently complex, offered a clear way to achieve the goals, and set up a firm ground for further evolution and scaling of the system.
In the next post, we will explore the implementation of the system, concrete technology choices, tactical design decisions and, most importantly, the role of the eventsourcing patterns and techniques to achieve the desired goals.
SLA is usually a “published” metric level, while “SLO” is the “internal goal”. In this case, SLA was not communicated externally, but was our “promise” to the business and sibling teams; SLO was my teams “inspirational” target. ↩︎
how long exactly was never explicitly mentioned, but for practical reasons, we targeted one hour. ↩︎
In those models, there are no clearly isolated capacity pools - underlying resources can be easily reallocated to serve other time slots or geographical areas. ↩︎
Each node will run multiple entities, but there will be only one instance of a certain entity. I.e. node1 runs
A,YandZand node2 runsX,B, andC. In other words, entity allocation to a node is exclusive - as long as an entity is allocated to any node, no other node is allowed to have another copy of the same entity. ↩︎